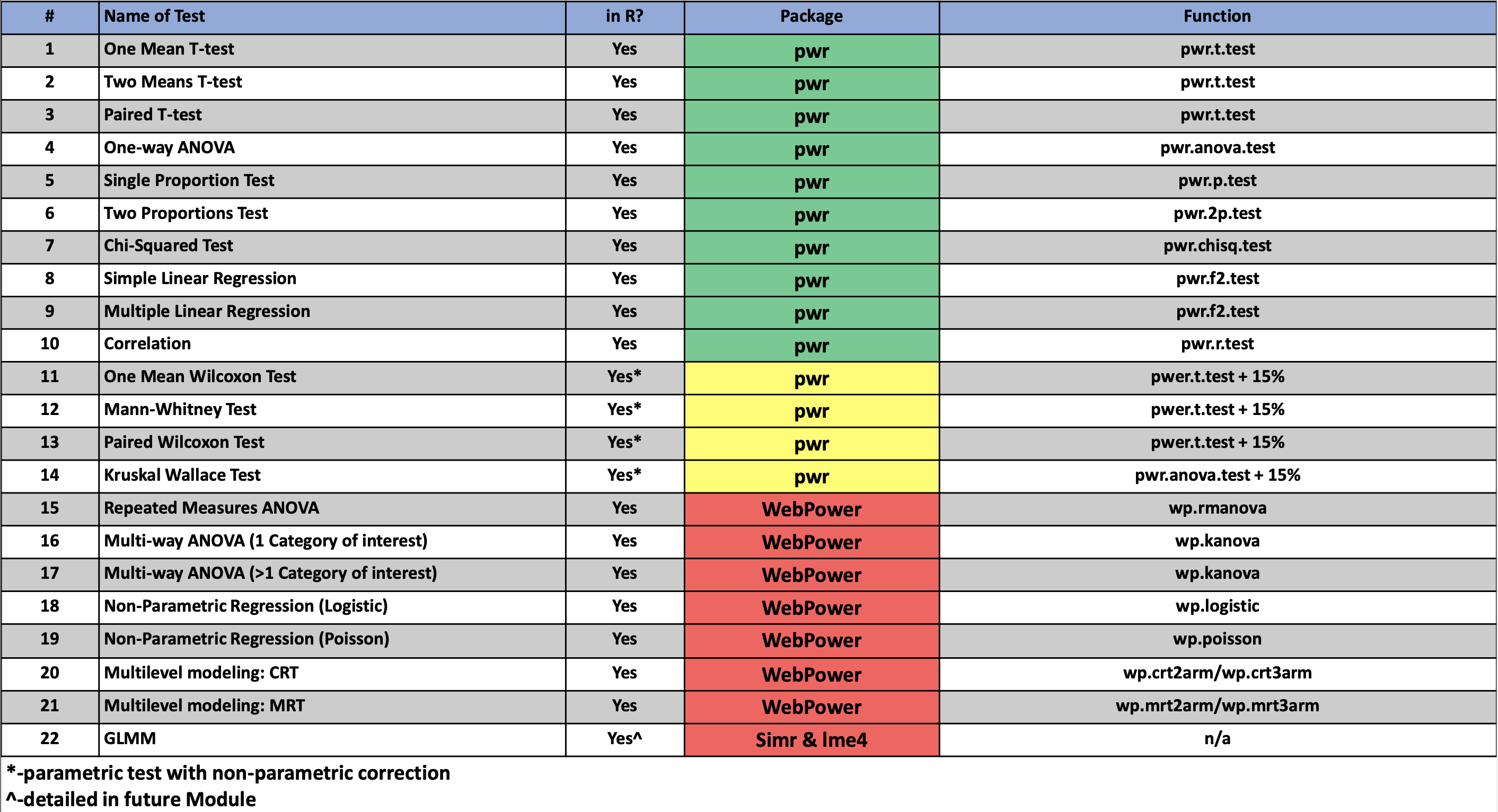
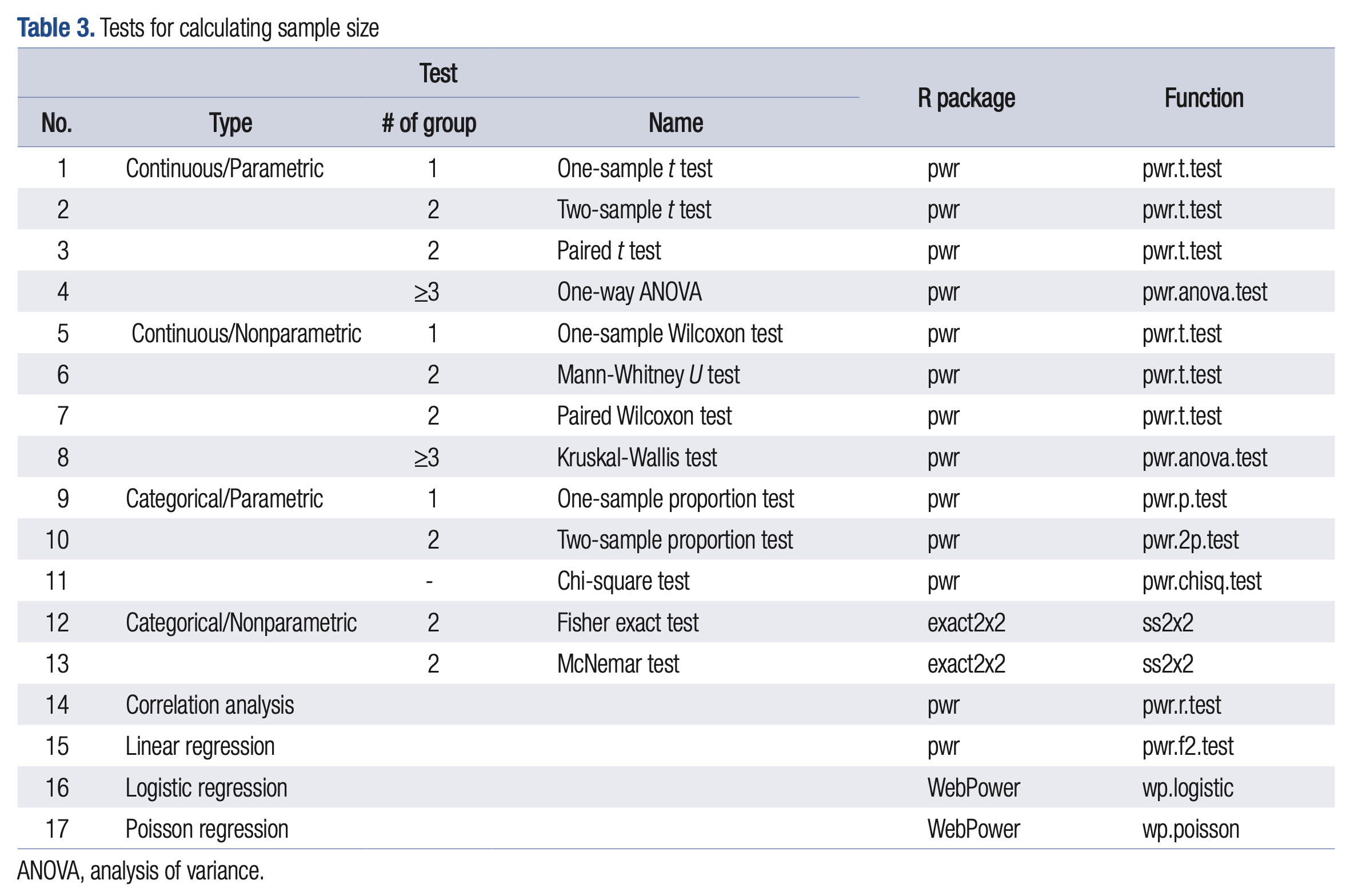
a significance of 0.05 and a power of 80% was established.
For nonparametric tests on continuous variables, as a rule of thumb, calculate the sample size required for parametric tests and add 15%
Effect Size
Effect size can be defined as ‘a standardized measure of the magnitude of the mean difference or relationship between study groups’
An index that divides the effect size by its dispersion (standard deviation, etc.) is not affected by the measurement unit and can be used regardless of the unit, and is called an ‘effect size index’ or ’standardized effect size
Whether an effect size should be interpreted as small, medium, or large may depend on the analysis method.
We use the guidelines mentioned by Cohen and Sawilowsky and use the medium effect size considered for each test in the examples below.
Conventional Effect Size
cohen.ES(test ="t", size ="medium")
Conventional effect size from Cohen (1982)
test = t
size = medium
effect.size = 0.5
Two Means T-test
tests if a mean from one group is different from the mean of another group for a normally distributed variable. AKA, testing to see if the difference in means is different from zero.
Effect size for t-test: 0.2 = small, 0.5 = medium, 0.8 = large effect sizes
\[
d = \frac{\mu_1 - \mu_2}{s_{pooled}}
\] The pooled standard deviation ( \(s_{pooled}\) ) is calculated as:
You are interested in determining if the average protein level in blood different between men and women. You collected the following trial data on protein level (grams/deciliter).
where ( \(n_j\) ) is the number of observations in each group, ( \(\bar{Y}_j\) ) is the mean of each group, and ( \(\bar{Y}\) ) is the overall mean.
Ex 1: Sx Option
You are interested in determining there is a difference in weight lost between 4 different surgery options. You collect the following trial data of weight lost in pounds
pwr.anova.test(k =4, f = eff_size3, sig.level=0.05, power =0.80 )
Balanced one-way analysis of variance power calculation
k = 4
n = 5.287432
f = 0.8054939
sig.level = 0.05
power = 0.8
NOTE: n is number in each group
Two Prop
Ex 1: Stat Scores
You are interested in determining if the expected proportion (P1) of students passing a stats course taught by psychology teachers is different than the observed proportion (P2) of students passing the same stats class taught by biology teachers. You collected the following data of passed tests.
Difference of proportion power calculation for binomial distribution (arcsine transformation)
h = 0.2101589
n = 355.4193
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: same sample sizes
Chi-Squared
Description: Extension of proportions test, which asks if table of observed values are any different from a table of expected ones. Also called Goodness-of-fit test.
Ex 1
You are interested in determining if the ethnic ratios in a company differ by gender. You collect the following trial data from 200 employees.
# A tibble: 200 × 2
gender ethnic
<chr> <chr>
1 male White
2 female White
3 male White
4 female White
5 male White
6 female White
7 male White
8 female White
9 male White
10 female White
# ℹ 190 more rows
table(employee$gender, employee$ethnic)
Am Asian Black White
female 11 3 21 65
male 1 14 25 60
Multiple regression power calculation
u = 1
v = 22.50313
f2 = 0.35
sig.level = 0.05
power = 0.8
# Nceiling(22.50313) +2
[1] 25
Multiple Linear Reg
Ex 1
You are interested in determining if height (meters), weight (grams), and fertilizer added (grams) in plants can predict yield (grams of berries). You collect the following trial data.
Multiple regression power calculation
u = 3
v = 13.69382
f2 = 0.8225024
sig.level = 0.05
power = 0.8
# Nceiling(13.69382) +4
[1] 18
Ex 2 (No Prior)
You are interested in determining if the size of a city (in square miles), number of houses, number of apartments, and number of jobs can predict the population of the city (in # of individuals)
cohen.ES(test ="f2", size ="large")
Conventional effect size from Cohen (1982)
test = f2
size = large
effect.size = 0.35
Multiple regression power calculation
u = 3
v = 31.3129
f2 = 0.35
sig.level = 0.05
power = 0.8
# Nceiling(31.3129) +4
[1] 36
Logistic Reg
p0 = \(Prob(Y=1|X=0)\): the probability of observing 1 for the outcome variable Y when the predictor X equals 0
p1 = \(Prob(Y=1|X=1)\): the probability of observing 1 for the outcome variable Y when the predictor X equals 1
In the context of using the wp.logistic() function from the “WebPower” package in R to calculate the sample size for a logistic regression, the arguments p0 and p1 are crucial. They represent the probabilities of the outcome occurring in the two groups you are comparing. Here’s how to determine these values:
Understanding p0 and p1:
p0: This is the probability of the event (or the success probability) in the control group or the group without the intervention/exposure.
p1: This is the probability of the event in the experimental group or the group with the intervention/exposure.
Obtaining p0 and p1:
These probabilities are usually obtained from prior research, pilot studies, or literature reviews. You need an estimate of how likely the event is in both the control and experimental groups.
If you’re testing a new treatment or intervention, p1 would be your expected success rate with the treatment, and p0 would be the success rate observed in the control group or with the standard treatment.
In the absence of prior data, expert opinion or theoretical assumptions might be used to estimate these probabilities.
Example:
Suppose you are studying a new medication’s effect on reducing the incidence of a disease. From previous studies, you know that 20% of patients (0.20 probability) typically show improvement with the current standard medication (p0). You expect that 35% of patients (0.35 probability) will show improvement with the new medication (p1).
Ex 1
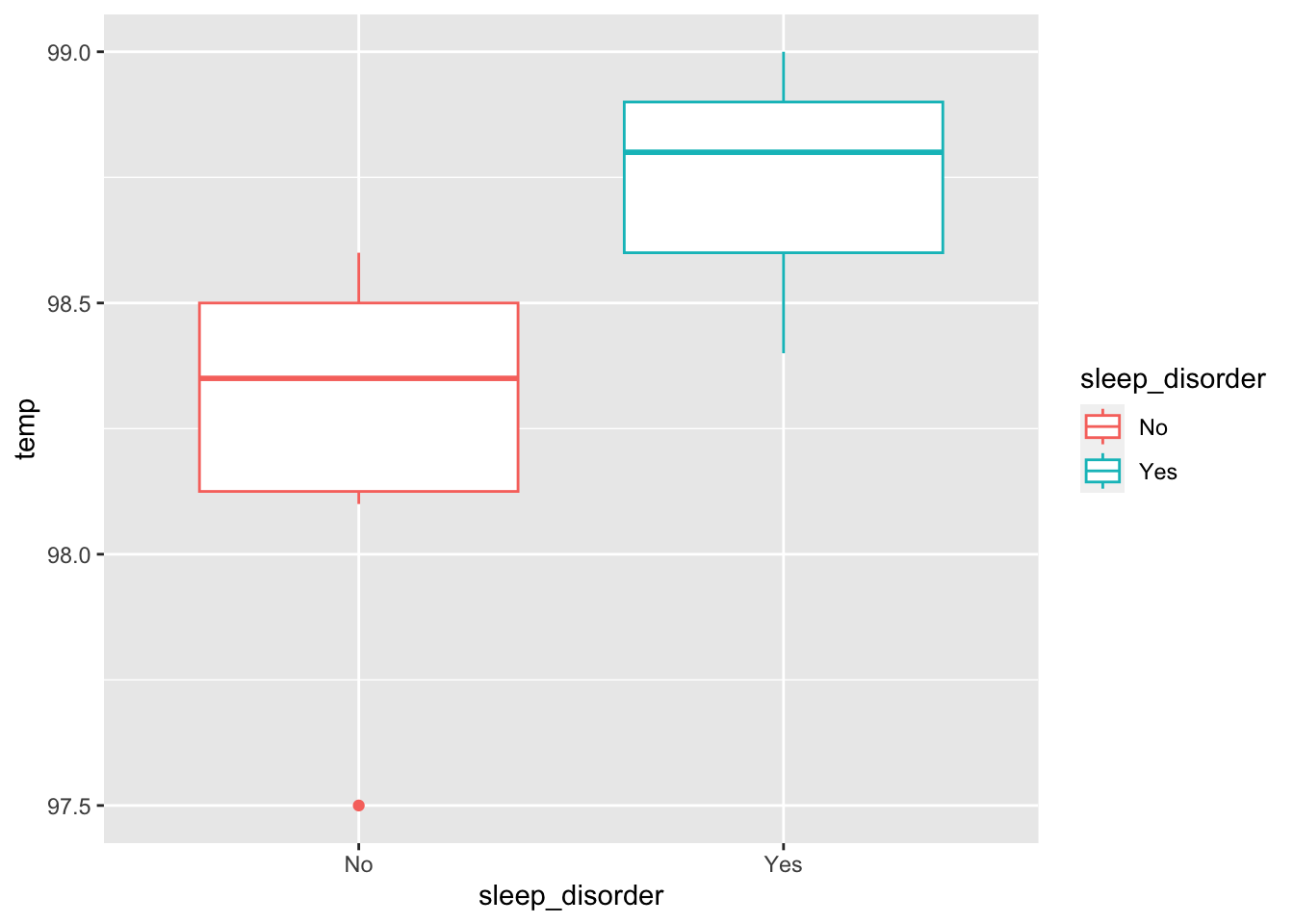
You are interested in determining if body temperature influences sleep disorder prevalence (yes 1, no 0). You collect the following trial data.